Challenges
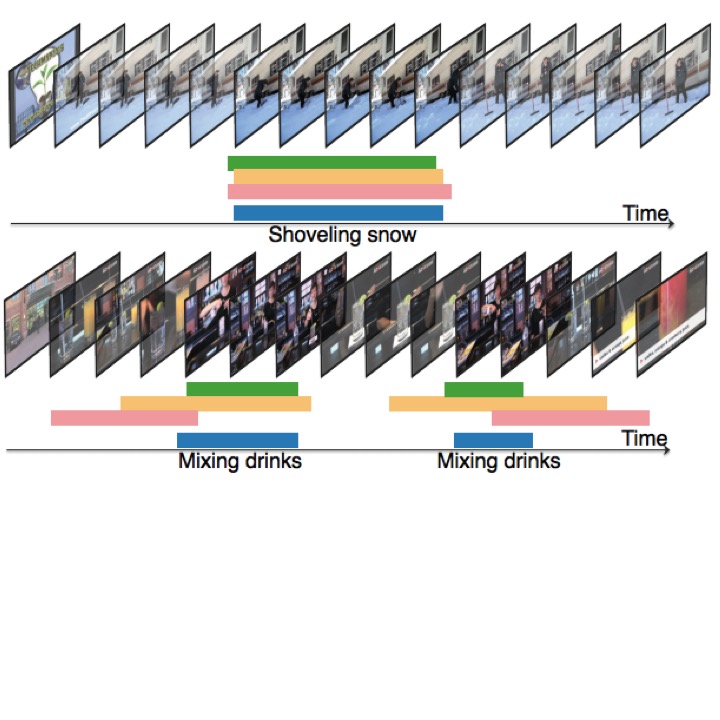
ActivityNet Temporal Action Localization
This task is intended to evaluate the ability of algorithms to temporally localize activities in untrimmed video sequences. Here, videos can contain more than one activity instance, and mutiple activity categories can appear in the video.
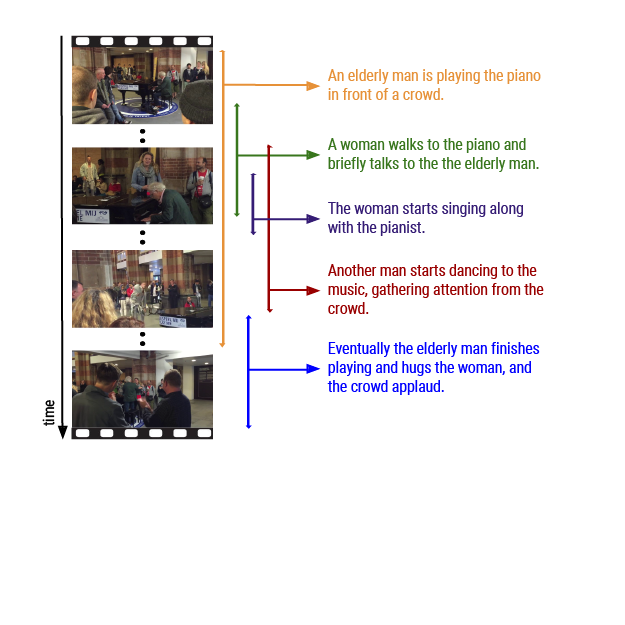
ActivityNet Event Dense-Captioning
This task involves both detecting and describing events in a video. For this task, participants will use the ActivityNet Captions dataset, a new large-scale benchmark for dense-captioning events.

AVA-Kinetics & Active Speakers
This challenge addresses two fundamental problems for spatio-temporal video understanding: (i) localize actions extents in space and time, and (ii) densely detect active speakers in video sequences.

ActEV Self-Reported Leaderboard (SRL)
The ActEV Self-Reported Leaderboard (SRL) Challenge is a self-reported leaderboard (take-home) evaluation; participants download a ActEV SRL testset, run their activity detection algorithms on the test set using their own hardware platforms, and then submit their system output to the evaluation server for scoring results, we will invite the top two teams to give oral presentations at the CVPR’22 ActivityNet workshop.

SoccerNet Challenge
The SoccerNet challenges are back! We are proud to announce new soccer video challenges at CVPR 2022, including (i) Action Spotting and Replay Grounding, (ii) Camera Calibration and Field Localization, (iii) Player Re-Identification and (iv) Ball and Player Tracking. Feel free to check out our presentation video for more details. The challenges end on the 30th of May 2022. Each challenge has a 1000$ prize sponsored by EVS Broadcast Equipment, SportRadar and Baidu Research. Latest news including leaderboards will be shared throughout the competition on our discord server.
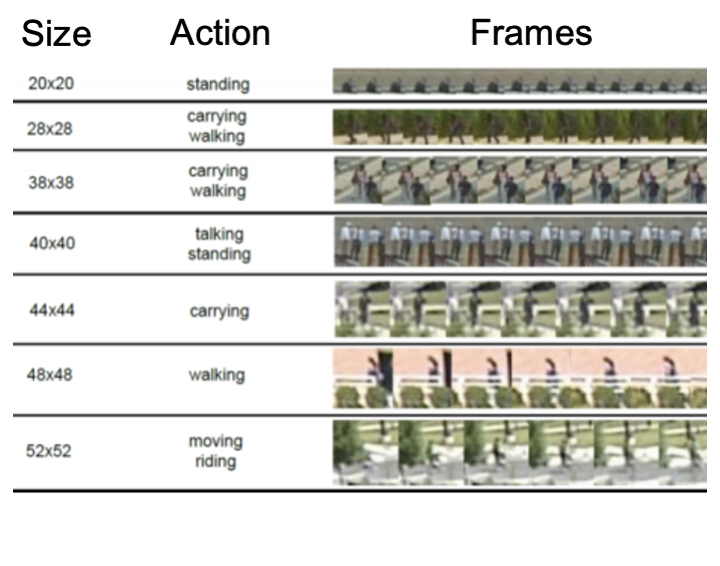
TinyActions
This challenge focuses on recognizing tiny actions in videos. There can be multiple activities present in a video and the videos can have varying range of resolution from 10x10 to 128x128 pixels. The task will run on TinyVIRAT benchmark dataset.

HOMAGE
This challenge leverages the Home Action Genome dataset, which contains multi-view videos of indoor daily activities. We use scene graphs to describe the relationship between a person and the object used during the execution of an action. In this track, the algorithms need to predict per-frame scene graphs, including how they change as the video progresses.