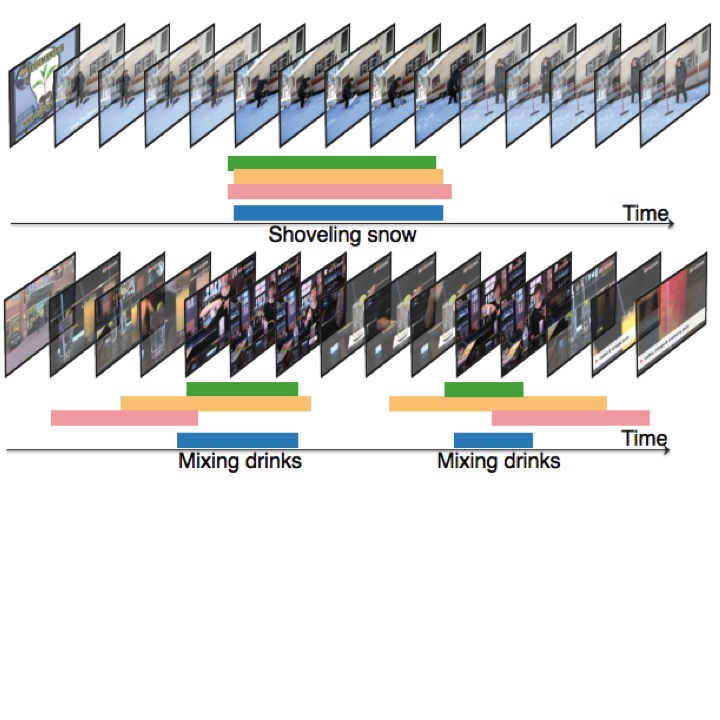
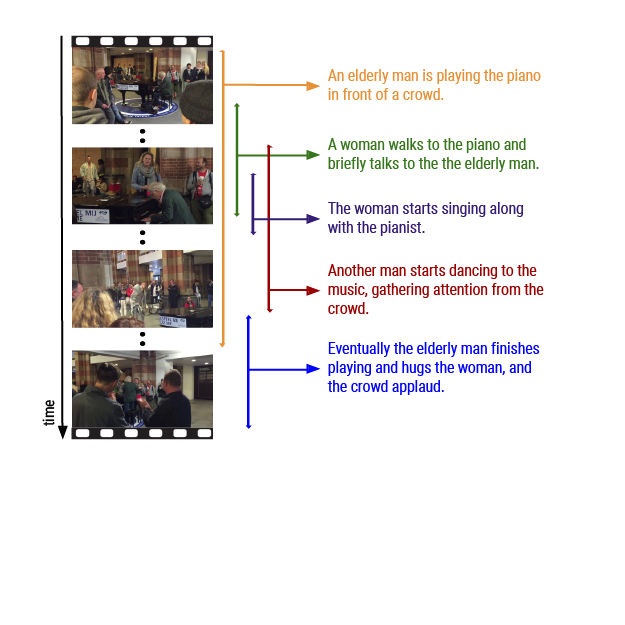
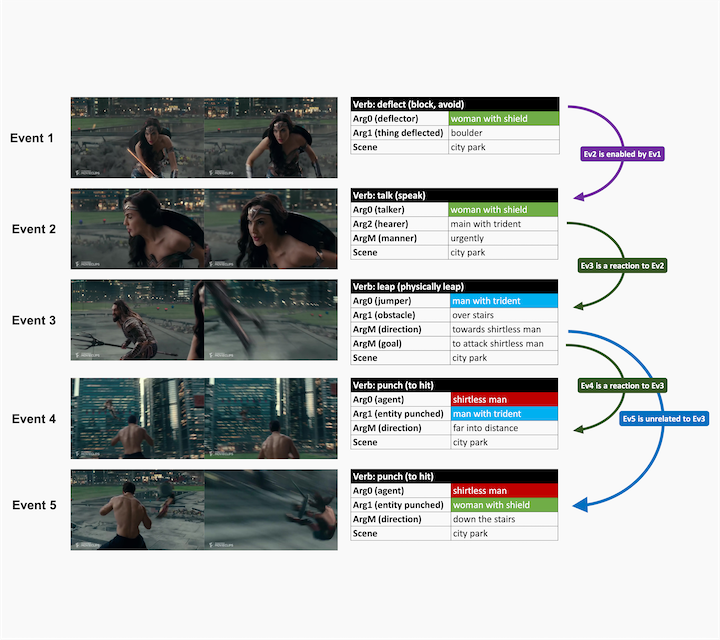
Action Recognition
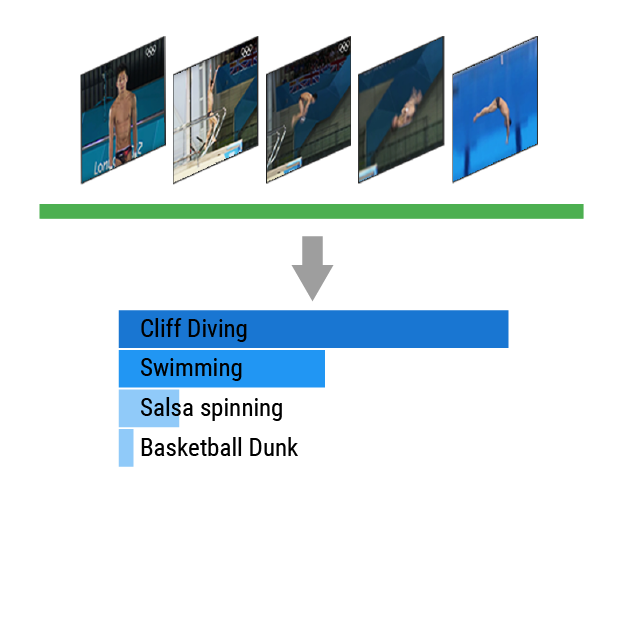
Kinetics-700 Challenge
The Kinetics 2021 challenge will have two tracks: supervised and self-supervised classification. Both will be restricted to using RGB and/or audio modalities from videos in the Kinetics-700-2020 dataset.
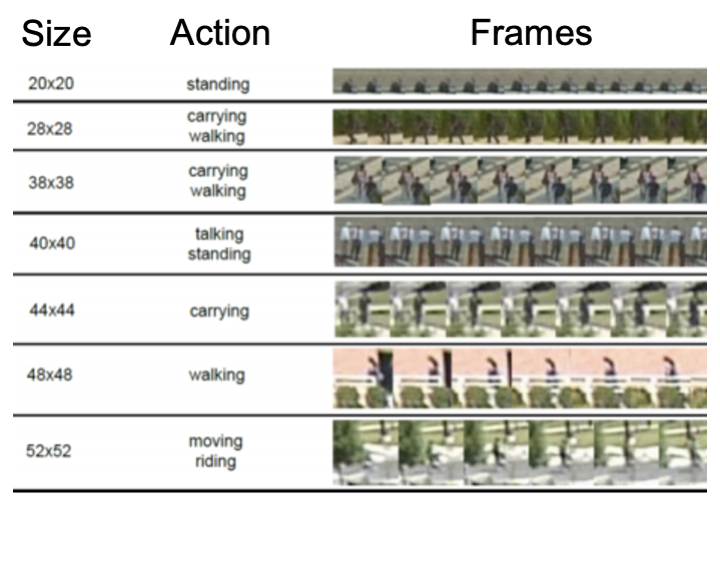
TinyActions
This challenge focuses on recognizing tiny actions in videos. There can be multiple activities present in a video and the videos can have varying range of resolution from 10x10 to 128x128 pixels. The task will run on TinyVIRAT benchmark dataset.