Baselines
We provide the results for a baseline proposal method (named Uniform Random) on the validation subset. Uniform Random: the center and length of each proposal are independently drawn from a uniform random distribution over the interval \( [0,d] \), where \( d \) is the video duration. This model scores \( 44.88\% \) on the metric described above.
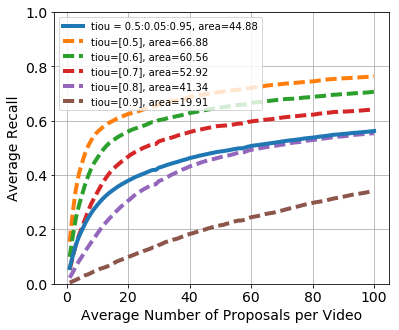
The dashed lines are for the recall performance when averaging over a single tIoU threshold, while the solid line is the average recall across all \( \text{tIoU} \) thresholds. As we can see, the recall performance is high for the smaller tIoU thresholds like \( 0.5 \) and \( 0.6 \), but it drops drastically for higher \( \text{tIoU} \)thresholds such as \( 0.8 \) and \( 0.95 \). Therefore, for a proposal method to score high on the evaluation metric, it would need to focus on getting relatively high recall for both low and high tIoU thresholds. Further reading can be found in this notebook.